Desde hace algún tiempo que en el trabajo tenemos cada vez con mayor frecuencia un problema bastante grave: hay tantas cosas nuevas de tantas personas que actualmente a SVN se le está haciendo la pista muy pesada y además, el no poder desactivar rápidamente características que no dan un buen resultado (AKA las que empeoran las ventas) complica las cosas aún más.
Por este hecho, en una de las reuniones del lunes (que por increíble que parezca se hacen todos los lunes), me pidieron si podía encontrar alguna solución a este nuevo problema que estaba surgiendo. A decir verdad, en un principio no le dediqué mucho tiempo al tema debido a que estaba ocupado con otras cosas hasta que el martes pasado, para el update del miércoles estuve todo el día clasificando código y viendo qué era apto para poder salir a producción y qué no. Por supuesto que esto representó un dolor de cabeza descomunal debido a que ocurría muy a menudo que más de una persona había hecho modificaciones a los mismos archivos en distintos lugares. Fue en este momento en que de verdad deseé que hubiera alguna herramienta que me permitiera fácilmente poder ir y revisar de un fix a otro de forma rápida e indolora. ¿El secreto? Esa herramienta existe, lo único malo es que intuitivo no es.
Las soluciones
La primera solución que pude divisar, era seguir ocupando la plataforma de SVN y ocupar parches. Los parches no son nada más que archivos que contienen una serie de instrucciones para poder llevar una cuenta de todas las modificaciones que se le han hecho a los archivos. Aunque esto suena muy bien, en la práctica es absolutamente inservible debido a que:
-
No soporta archivos binarios. Olvídense de agregar fotos y otros.
-
No soporta la creación de archivos nuevos. Aunque hay maneras de sobrellevar esto, es bastante engorroso.
-
Así como no soporta la creación de archivos, tampoco soporta el borrado de éstos.
-
Como no se pueden crear o borrar archivos, olvídense de renombrar archivos.
-
Tiene un pésimo soporte para múltiples ediciones en el mismo archivo, sobretodo si se acerca siquiera a las líneas que estén cerca de la edición principal, típicamente en la zona de 3 a 4 líneas cerca de la edición.
-
Tiene algunos problemas con algunos signos como el del € y otros (aunque el único otro que he detectado es cierto tipo de backtick) donde no indica error alguno y simplemente omite esas líneas sin siquiera avisar.
Con esos problemas, ya pocas ganas quedan de querer implementar en la vida real los parches de SVN.
La segunda solución fue empezar a ocupar el esquema de trunk, branches y tags, pero lamentablemente, en el trabajo ya se ocupan los tags y por otro lado, el merge de vuelta puede resultar en un infierno si se da el caso de que dos desarrolladores hayan hecho algún cambio en un mismo archivo y líneas en un código que ya ha sido actualizado con una nueva versión. Es difícil de explicar, y para no explayarme más en temas intrascendentes, imagínense que es como preguntarle a un católico qué opina del divorcio gay. (Chiste prestado de @hermeselsabio, que aparte de hacer críticas maestras también es chistoso).
Sale SVN, entra Git
Cuando fui a la última conferencia de PHP, me sorprendió que cuando se hablaba de control de versiones, el único motor del que se habló era Git. SVN por otro lado; era como un tema tabú; todos lo conocían pero nadie se atrevía a hablar del “otro”, la gente te miraba raro y con cierto dejo de desprecio en sus ojos en cuanto pudiera haber algún comentario siquiera de Subversion. Me di cuenta en ese momento de que si todos los capos (no pueden ser todos hipsters cierto?) estaban ocupando y hablando de Git… ¿algo bueno tendría que tener o no?
Fue en ese momento que consideré la opción de ver el tema un poco más en serio y empezar a investigarlo, aprovechando que teníamos un problema emergente en la oficina. Y es aquí donde me di cuenta de que había perdido demasiado tiempo con SVN y que debí haberme cambiado a Git hace mucho tiempo atrás. En el trabajo teníamos un problema muy similar a la imagen de abajo, y dicen que las imágenes son mil palabras, así que el siguiente esquema clarificará bastante:
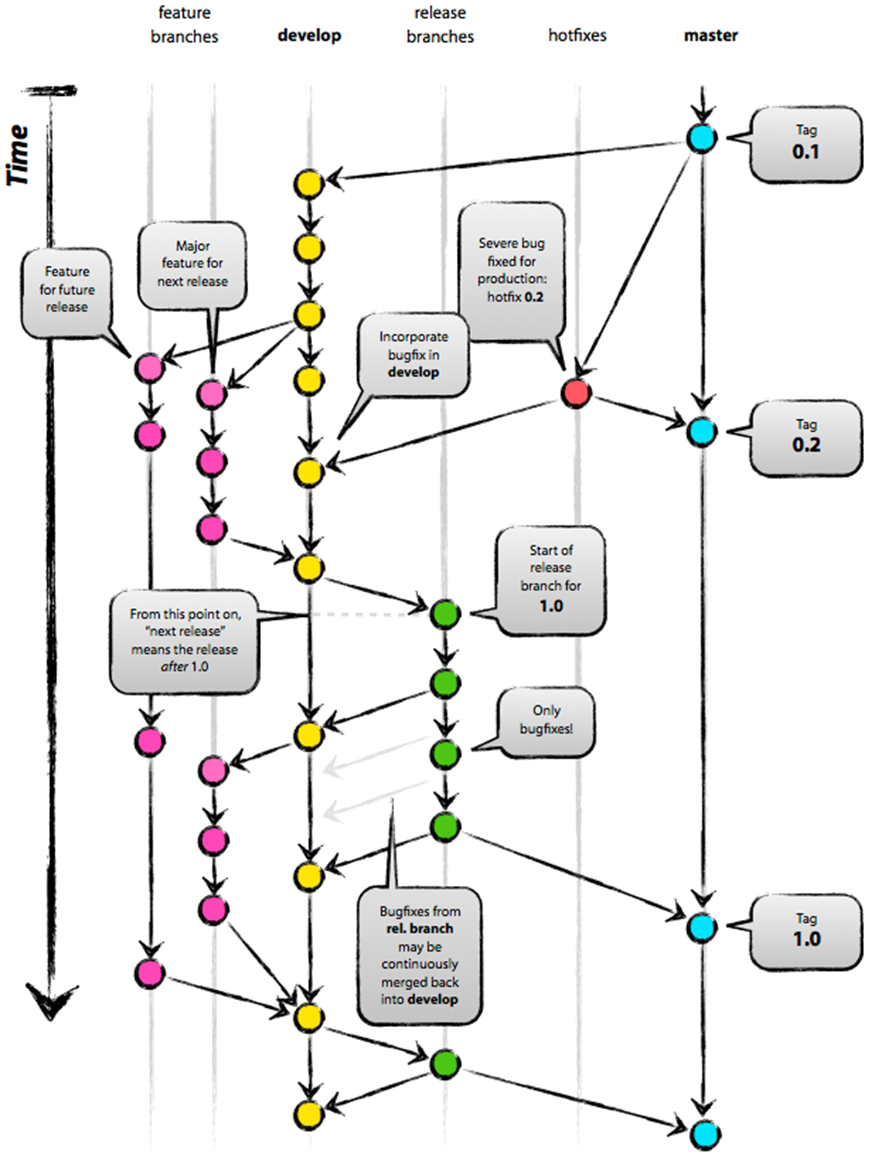
Click en la imagen para agrandarla
Como podrán apreciar en el esquema de arriba, Git es especializado en justamente unir cosas (la famosa operación llamada “merge”) y dejar esos cambios unificados como el producto final. Cuesta un poco entender el esquema al principio, pero después de asimilarlo queda bastante más claro.
Los primeros pasos en Git
La instalación del server a-la-svn la dejaré para un post posterior, pero otra de las principales diferencias entre SVN y Git es que uno es su propio repositorio y no es necesario un repositorio principal, pero de todas formas es posible trabajar con un repositorio centralizado. Claro que la instalación de ésta no parece ser tan simple a primera mano. De todas formas, será material para un próximo artículo.
La instalación en sus propios computadores es bastante simple y hay instrucciones para Linux, Mac OS X y el infame Windows por todos lados, es cosa de buscar en Google no más. Les recomiendo le echen un vistazo a la página oficial de Git para que de ahí instalen el cliente/servidor.
Lo primero que hay que aprender de Git es que lo más importante es que uno nunca debería trabajar en master, que es por así decirlo el repositorio principal y la que se debería ocupar en producción. (Para los más críticos: sé que no tiene por qué ser así pero asumamos eso por el momento). La forma correcta de trabajar es que uno crea un nuevo branch, haga todo el trabajo en ese branch y posteriormente lo una con master. De esa forma, es posible poder trabajar en varios puntos a la vez y tener los distintos desarrollos totalmente separados uno del otro sin afectar la rama en producción. Sólo en el punto en que vayan a implementar los nuevos desarrollos en producción, hacen un merge de todas aquellas cosas nuevas en master.
Lo segundo que hay que aprender es que ya no existe un solo commit: existen en realidad dos formas de hacer un commit. La primera es el commit que es el que hace uno en su propia máquina, y la segunda operación es el push que es el que se hace a uno o todos los servidores centralizados, que es la operación que más se asemeja al de svn.
Aparte de eso, existen algunos comandos más que son importantes:
git pull [opciones]: es el famoso “svn update” del mundo svn.
git checkout [opciones]: Nada tiene que ver con el checkout de svn, en el caso de Git, checkout es el comando que sirve para cambiar entre branches.
git clone [opciones]: Es el checkout de svn. Mediante este comando estaremos clonando un proyecto.
Existe casi una infinidad de comandos más (de hecho, hay más de 100), así que si quieren conocer algo más avanzado les recomiendo visitar la manpage de Git. En ella hay una breve explicación de todos los comandos disponibles y qué hace cada uno.
¿Y qué es Github?
Sin duda alguna, más de alguna vez habrán escuchado hablar de Github. En principio, no es nada más que un servidor centralizado. La gracia de Github es que tiene dos modalidades: una gratuita y otra de pago. En la versión gratuita, podrán hostear su proyecto en un servidor principal propiedad de Github pero ésta tendrá que ser público. Si quieren montar algún proyecto privado tendrán que pagar, y esto depende de cuántos proyectos privados querrán montar. En esta página hay más información acerca de los pagos. En resumen, no es nada más que un servidor centralizado que les facilitará algunas cosas. También pueden montar su propio servidor con Gitolite de forma que ustedes mismos puedan administrar usuarios, accesos y permisos, pero eso como ya mencioné previamente es material para el próximo post.
Conclusiones
Git es una de las herramientas más avanzadas que existen para control de versiones. Entre sus desventajas cuentan el hecho de que tiene una curva de aprendizaje no lineal, y que, tal como todos los proyectos grandes, existe demasiada documentación donde lamentablemente la gran mayoría está un poco obsoleta, aunque no al nivel de PHP. Entre las ventajas es que después de probar Git, es difícil que se pueda encontrar una mejor herramienta que haga las cosas de mejor manera, ya que todo lo que Git hace, lo hace muy bien. Yo ya llevo trabajando un tiempo con Git y hasta el momento nunca he tenido un conflicto, cosa que con SVN me pasa en casi cada commit grande que tengo. La forma de resolver conflictos de Git es muy elegante y también muy buena. Por otro lado, no hay que olvidar que el puntapie inicial de Git fue dado por Linus Torvalds, un personaje bastante importante para aquellos que no lo conozcan.
Otra desventaja de Git es que no indexa directorios, pero esto es solucionable colocando un archivo llamado .gitignore que ignore todo lo que esté dentro de la carpeta, EXCEPTO el archivo mismo. De esta forma, Git indexará el directorio.
Aparte de entonces una curva de aprendizaje no lineal y el hecho que no indexe directorios, no le he podido encontrar mayores problemas a Git. Importar un proyecto grande de SVN a Git es bastante trivial y puede dar algunos problemas sobretodo en servidores con muchos procesadores, pero tiene fácil solución. Todo eso se verá en el próximo post.
Hasta la próxima.