¿A quién no le ha pasado que sabemos que un proceso determinado es lento y queremos optimizarlo para que de esta forma ande más rápido y los gerentes te promocionen a sub-gerente general para -tiempo después- casarte con la hija de alguno de ellos, unos meses después y gracias en parte al tremendo éxito de esa misma optimización y también porque tu nuevo suegro ya encontró el heredero perfecto, terminar manejando la multinacional y -de pasada- un Lamborghini Y un Ferrari del año? Bueno, aunque suena muy prometedor, cada vez que intentamos optimizar nuestro código no parece surtir efecto alguno dejándonos sin esa posibilidad de primera promoción que hará despegar tu carrera profesional a las nubes.
El gran secreto detrás del por qué nuestras optimizaciones no parecen surtir efecto es lamentablemente debido a una razón bastante simple: el 95% del tiempo creemos o intuimos que cierto pedazo de código es el lento cuando, en la vida real, ese 5% que en realidad descartamos porque es demasiado simple, es el que está provocando el cuello de botella. ¿Quieres saber cómo sigue la historia? Haz click en leer más entonces.
Afortunadamente, existe gente muy grande de corazón y que han vivido en carne propia todas estas aventuras; y han decidido compartir la solución para que de esta forma, todos los programadores de PHP del mundo tengan la posibilidad de alguna vez en su vida manejar un Audi R8 sin ese sentimiento del miedo a incluso hacerle una raya a la pintura.
Esta solución se llama hacer un perfilamiento o profiling en inglés, aunque aclaro que usaré las palabras en español para referirme al tema. El perfilamiento es, en esencia, nada más que medir en términos de tiempo y memoria cada parte de un request. Para esto, lo primero que necesitamos es la última versión (estable) de xDebug, extensión de PHP que nos ayudará para hacer el perfilamiento, y ya que estamos en esas, recomiendo también bajar APC, intl y las dependencias necesarias para el conector a mssql, el cual es un tema del cual hablé hace poco en este post. Demás está decir que nunca hagan esto en su servidor de producción, he visto archivos de perfilamiento que llegan a pesar 500MiB, con lo cual nos podríamos quedar sin memoria en unos cuantos segundos. Además, la aplicación andará el triple de lento con xdebug y más encima perfilando porque mal que mal está evaluando CADA regla que estemos ejecutando.
Empezando por lo principal
Lo primero a lo que deberemos prestar atención es a la configuración de xDebug ya que ella nos permitirá generar los archivos de perfilamiento para que de esta forma podamos estudiarla con mayor profundidad. Ahora bien, le coloco bastante énfasis a lo tedioso que es estudiar un archivo de perfilamiento porque de verdad lo es. Requiere de mucha concentración para no equivocarse y además van a terminar con un Excel del tamaño de una base de datos chica porque lamentablemente una sola medición no es ni objetiva ni representativa. Cuando empiecen con sus primeros tests verán que de cada 10 pasadas, en al menos uno PHP tiene un pequeño hipo que hace que cierta función demore el triple o más en devolver una respuesta, así que para obtener resultados que sean útiles y representativas, recomiendo al menos 10 pasadas y de ellas, sacar un promedio. Además servirá bastante si se conocen el framework o sistema que ocupen de memoria.
Pero bueno, empecemos por lo primordial que es la configuración de xdebug. Abrimos nuestro php.ini y creamos (o descomentamos si seguiste los pasos del post previo) las siguientes líneas bajo el apartado [xdebug]:
xdebug.profiler_enable = On
xdebug.profiler_output_dir = "/tmp/cachegrind"
xdebug.profiler_output_name = callgrind.out.%p
xdebug.profiler_enable_trigger = 0Ahora bien, esta configuración quiere decir en palabras muy breves lo siguiente: Habilitamos el profiler (con xdebug.profiler_enable), decimos que escriba a /tmp/cachegrind/ (con xdebug.profiler_output_dir, este mapa deberemos crearlo manualmente y asignarle permisos 777), también le decimos que el archivo de salida tenga como nombre “callgrind.out.%p” (con xdebug.profiler_output_name, donde %p representa la pid del proceso, click acá para más modificadores) y además deshabilitamos expresamente el trigger (mediante xdebug.profiler_enable_trigger) el cual significa en muy breves términos que no necesitamos tener establecida una cookie o pasar un parámetro GET o POST para poder obtener nuestro archivo de perfilamiento. Si desean mayor información con respecto a todos los parámetros con los cuales se puede configurar xdebug, visiten esta página (del desarrollador oficial que entre paréntesis vi en una conferencia hace poco el fin de semana pasado y donde habló justamente del mismo tema xD) que las lista todas.
Creando un escenario de pruebas
El siguiente paso es reiniciar apache (doh) y ejecutar nuestra primera prueba. Para facilitar la explicación, me di el gusto de crear una pequeña aplicación que recorre una carpeta con algunas imágenes. También, a modo de dar a entender el cómo podemos comparar nuestro resultado final con el inicial (acelerar la aplicación) entregaré otra versión que hace exactamente lo mismo pero que emplea cache para almacenar los resultados temporales. Esta aplicación la pueden bajar desde este link y poner en sus máquinas para probar que efectivamente todo funciona como debe ser. Acepto de regalo cualquier cosa que venga en la carpeta de imágenes por cierto, no se preocupen si es muy humilde, igual acepto.
Lo primero que tienen que hacer después de bajar este archivo, es descomprimirlo en la máquina donde van a hacer el perfilamiento y dar permisos 777 a la carpeta llamada “cache”. Enseguida ejecutan el primer ejemplo check-files.php. Es importante que desde que activen el perfilamiento a la ejecución de este script no ejecuten nada más de lo contrario se van a llenar de archivos de perfilamiento y frente a eso es difícil seguir la pista.
Lo siguiente que haremos será ir a la carpeta /tmp/cachegrind/, donde, si todo está bien, veremos 1 archivo que tiene como nombre el patrón de arriba. Les aconsejo que respalden este archivo en otro lado, lo borren y luego ejecuten el mismo request unas cuantas veces más. Mientras más mejor, pero hay que tener en cuenta que el tiempo necesario para analizarlo posteriormente crecerá también.
Estudiando la salida
Una vez que tengamos hartos ejemplos, viene la parte más interesante: el estudio del archivo de perfilamiento. Para esto puedo recomendar:
WebGrind: Es el menos recomendado del grupo ya que es el más simple pero también el más enredado para presentar la información. Además, presenta muy poca de ella.
MacCallgrind: Es el mejor programa para Mac que pude encontrar. Lo único malo es que sólo permite abrir archivos de máximo 3MiB lo cual parece algo bastante exagerado, pero si tomamos en cuenta que el perfilamiento de un simple listado de directorio generó un archivo de 28KiB y la versión más avanzada uno de 108KiB (que sólo hace algunas cosas más no más) nos podremos dar cuenta que 3MiB no es nada. Una página medianamente grande generará fácilmente un archivo de 5MiB. Una vez ejecuté un cron más o menos largo y el archivo generado fue de 1.5GiB, así que ojo que crecen bastante.
Por último, la mejor alternativa que encontré (y que siendo nativamente de Linux hicieron un port a Windows) es KCacheGrind. Si tienen Linux, lo más probable es que sea un simple yum install kcachegrind o su equivalente en apt-get, pero para Windows tendrán que hacer click acá.
Acá me gustaría detenerme un poco y recomendarle a todos los que ocupan Windows lo siguiente: Si ya llegaron a este punto de querer hacerle un seguimiento a su código, les recomiendo encarecidamente que empiecen a ocupar Linux como sistema al menos para trabajar. La razón es bastante simple: cualquier acción más allá de hacer perfilamiento (especialmente si quieren crear sus propias extensiones en C para PHP) serán días de instalar herramientas bastante complejas para Windows que en primer lugar siempre fueron destinados para Linux y lo más gracioso de todo es que al final de la instalación de todas estas herramientas su pc tendrá casi una máquina virtual corriendo Linux por detrás. La misma tarea, pero hecho en Linux, lo que significa instalar una máquina desde cero, todas las dependencias y finalmente ejecutar su primer “Hola mundo” desde C no les va a costar más allá de 2 horas. En serio se ahorrarán mucho tiempo y malos ratos y además aprovecharán de conocer ese sistema que hace correr el 85% de internet y eso por algo es.
En fin, siguiendo con el tópico en cuestión, tendrán una pantalla muy parecida a la siguiente en Mac (donde tengo abierto 2 instancias):
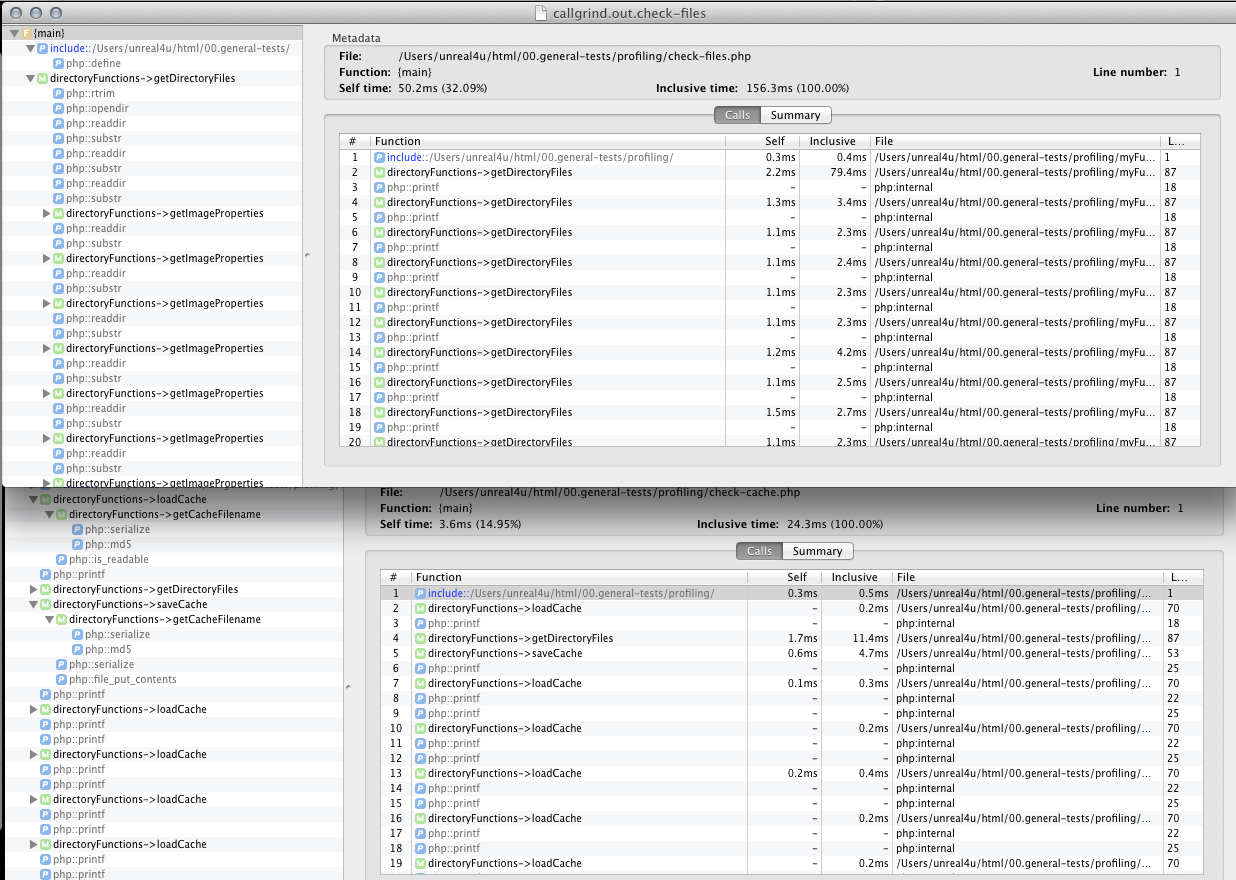
O en Windows/Linux:
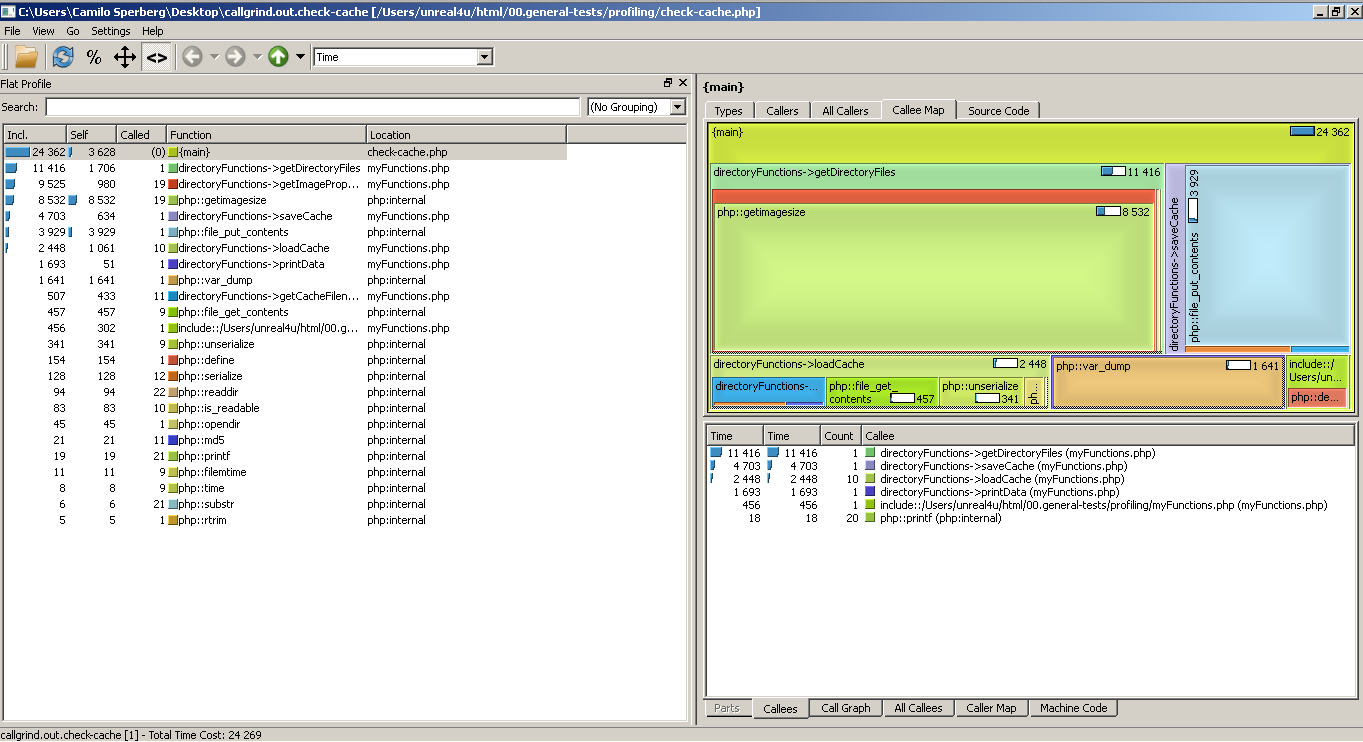
Lo único que les queda por hacer llegado este punto es agarrar una planilla de Excel y empezar a sacar porcentajes, promedios, sumas y todo eso siguiendo el método científico para que de esta forma puedan identificar los cuellos de botella.
Identificando puntos críticos y mejorando
Por supuesto que hasta el momento ha sido todo muy bonito pero no hemos tomado ninguna acción. Parto por aclarar que elegí el tema de recorrer un directorio de imágenes por una razón bastante simple: es fácil de optimizar ya que basta crear un archivo caché y consultar este archivo que andar recorriendo una carpeta con posibles miles de imágenes. Con eso se nota instantáneamente cualquier mejora al sistema. Sin embargo, en la vida real detectar un cuello de botella es bastante complejo y es acá donde el gráfico de KCacheGrind viene a ser definitivamente LA herramienta más útil del planeta, ya que en un solo vistazo se puede apreciar qué función(es) es/son las que están haciendo el cuello de botella. Nuevamente, en este caso es bastante fácil de detectar, pero así se ve un screenshot del sistema en producción en la empresa donde trabajo:
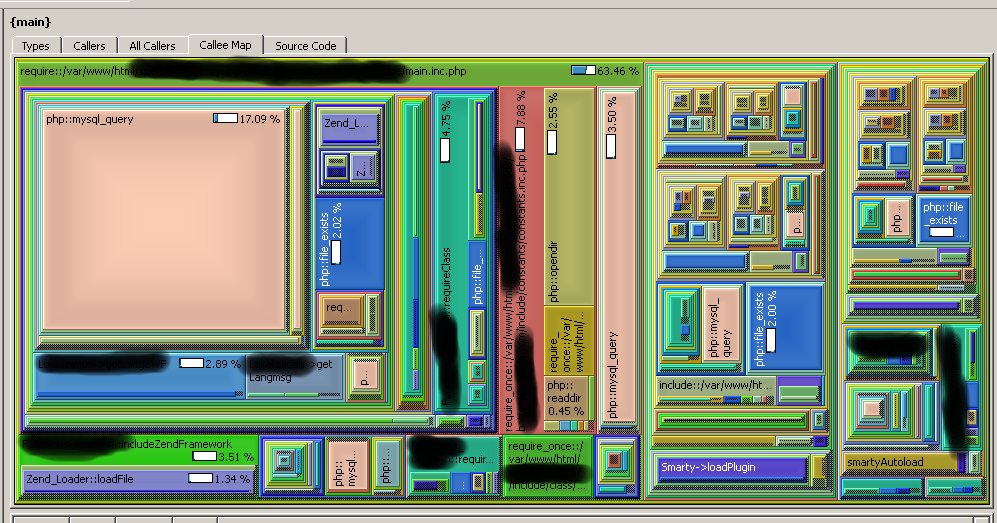
En el ejemplo, aparte del más obvio que es la query a la base de datos, hay literalmente miles de includes, funciones y classes que se cargan en el sistema base y que, en su conjunto, arman el sistema. Ese es el tipo de informes que hay que revisar y entender para que de esta forma, se pueda llegar a optimizar lo que es importante y no lo que creemos que pueda ser importante.
Implementando la solución
Ya una vez que hayan estudiado el tema, les recomiendo que hagan lo mismo con el script que guarda una cache llamado check-cache.php. Nuevamente, mismo procedimiento anterior: correr unas 10 veces asegurándose que entre pasada y pasada limpien la cache (Debería haberlo hecho en el script pero se me olvidó agregarlo). Una vez que tengan los resultados listos, podrán ver (de forma objetiva) que la segunda solución es aproximadamente 6,5 veces más rápido que la primera. Teniendo en cuenta que es sólo un pequeño directorio con 19 imágenes chicas ya es harta la diferencia. El tiempo a todo esto en KCacheGrind se puede ver en la segunda columna, la que dice “incl.” En la imagen de arriba, se puede ver que {main} (el proceso principal) demora en total 24,362 milisegundos, lo cual comparado con los 156,3 milisegundos del primer caso ya nos daría un boost de velocidad bastante grande teniendo en cuenta que nuestra aplicación no hace nada más que recorrer un directorio. En la vida real sin embargo, aunque pueden dar boosts de velocidad a un cierto proceso o subproceso, es muy complicado dar un boost general.
Conclusiones
El perfilamiento es algo que debería hacerse de vez en cuando casi como una auditoría para identificar posibles puntos críticos e intentar mejorar estos. Sin embargo, debo resaltar nuevamente la importancia de identificar correctamente los cuellos de botella y dejar de lado aquellos que aún pudiendo ser mejorados en algunos microsegundos, en realidad no vale la pena la inversión de tiempo y posibles bugs que puedan afectar negativamente el sistema. Entre que se demore 0.0005s y 0.0003s ni el usuario ni el servidor notarán un cambio real. Muy distinto en cambio, es si pueden mejorar un proceso de 0.7s a 0.2s (o mejor aún, 0.02s), lo cual ya es medio segundo menos en cada request a ese proceso en particular y que un usuario normal puede notar fácilmente.
¿Mi consejo? Identifiquen todos aquellos procesos que toman más de un 10% del tiempo total del script y enfóquense en mejorar eso, de lo contrario perderán tiempo (y sus jefes o ustedes mismos plata) en algo que en realidad ni siquiera vale la pena.
Cualquier duda con respecto a este post, pueden dejar sus comentarios más abajo.